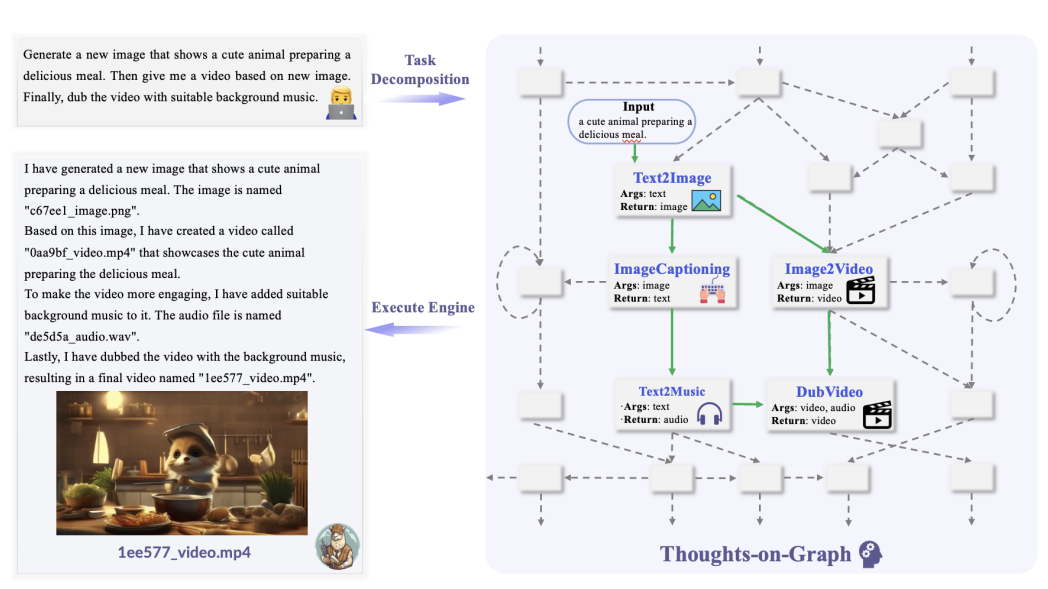
We present ControlLLM, a novel framework that enables large language models (LLMs) to utilize multi-modal tools for solving complex real-world tasks. Despite the remark- able performance of LLMs, they still struggle with tool invocation due to ambiguous user prompts, inaccurate tool se- lection and parameterization, and inefficient tool scheduling. To overcome these challenges, our framework comprises three key components: (1) a task decomposer that breaks down a complex task into clear subtasks with well- defined inputs and outputs; (2) a Thoughts-on-Graph (ToG) paradigm that searches the optimal solution path on a pre- built tool graph, which specifies the parameter and depen- dency relations among different tools; and (3) an execution engine with a rich toolbox that interprets the solution path and runs the tools efficiently on different computational devices. We evaluate our framework on diverse tasks involving image, audio, and video processing, demonstrating its superior accuracy, efficiency, and versatility compared to existing methods.
By using the multimodal interaction framework ControlLLM, it is possible to use LLM as the main controller, integrate tools with different functions as plugins, and use the proposed Thoughts on Graph (TOG) algorithm for reasonable task decomposition, tool selection, and efficient tool execution tuning, making the model more efficient and accurate in understanding user needs.
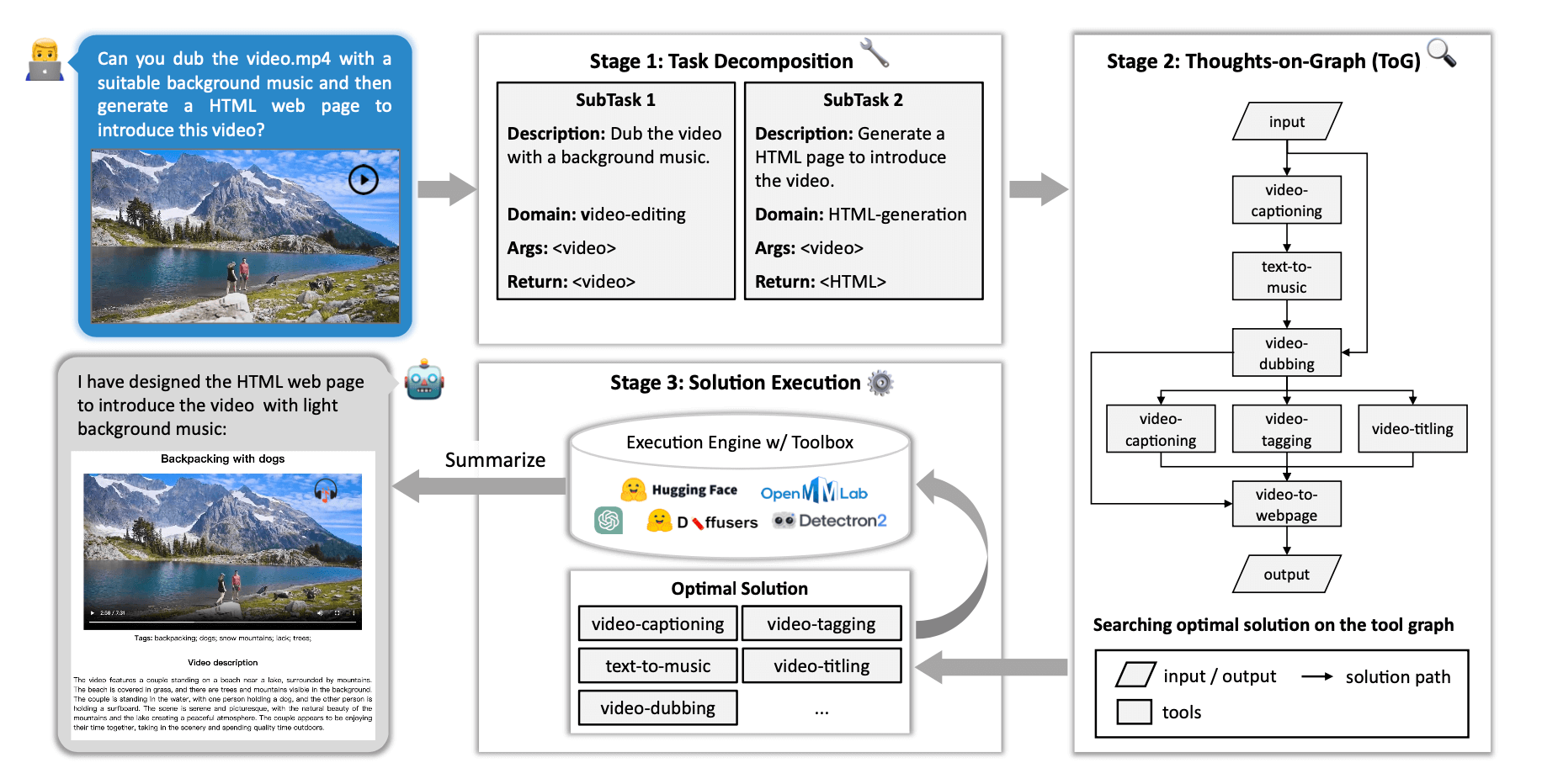
The framework consists of three stages. The first stage is task decomposition, which parses the user input into several subtasks. Then, in Stage 2, ToG utilizes a depth-first search algorithm to find the optimal solution for each subtask. The execution engine in the last stage executes the solution and returns the output to users. We here use the example of generating a web page for the video to illustrate our method.
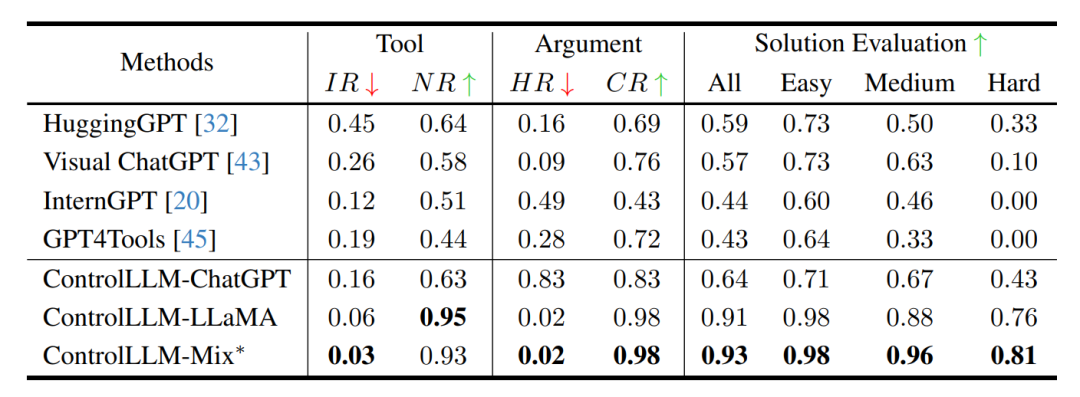
The table shows that our framework supports more features that facilitate the user experience of multi-modal interaction. It proves the high scalability of our framework.

Three implementations were provided using ControlLLM, which were compared with HuggingGPT, Visual ChatGPT, InternGPT, and GPT4Tools. It can be seen that it exhibits excellent performance in tool selection, parameter inference, and overall solution effectiveness, surpassing the most advanced methods in the field.






@article{2023controlllm,
title={ControlLLM: Augment Language Models with Tools by Searching on Graphs},
author={Liu, Zhaoyang and Lai, Zeqiang and Gao Zhangwei and Cui, Erfei and Li, Ziheng and Zhu, Xizhou and Lu, Lewei and Chen, Qifeng and Qiao, Yu and Dai, Jifeng and Wang, Wenhai},
journal={arXiv preprint arXiv:2305.10601},
year={2023}
}